
缓存(Caching)是系统优化中简单又有效的工具,只要简单几行代码或者几个简单的配置,我们就可以利用缓存让系统的性能得到极大的提升。
1. 什么是缓存
缓存是一个用来保存数据的区域,从缓存区域中读取数据的速度比从数据源读取数据的速度快很多。
在从数据源(如数据库)获取数据之后,我们可以把数据保存到缓存中。

下次再需要获取同样数据的时候,我们可以直接从缓存中获取之前保存的数据,而不是要再去数据源获取数据。

由于从缓存中读取数据的速度比从数据源中读取数据的速度更快,因此使用缓存能提高系统数据的获取速度。
如果从缓存中获取了要获取的数据,就叫作”缓存命中”;
多次请求中,命中的请求占全部请求的百分比叫作”命中率”;
如果数据源中的数据保存到缓存后,发生了变化,就会导致”缓存数据不一致”。
在Web开发中,存在着多级缓存,比如在浏览器端存在”浏览器端缓存”,在网关节点服务器中也可能存在”节点缓存”,在Web服务器上也可能存在”服务器端缓存”。

对于用户发出的请求,只要在任何一个节点上命中缓存,请求就会直接返回,而不会继续向后传递。
HTTP中的RFC7234规范中对缓存处理进行了规定,如果客户端、CDN节点、API网关节点服务器、反向代理服务器、Web服务器等遵守这个规范,它们就会按照缓存相关的报文头中的设置对缓存进行控制。
.NET Core中的响应缓存(Response Caching)就是遵守RFC 7234规范的缓存控制机制,它可以对浏览器缓存、CDN节点缓存、服务器端缓存进行统一的控制。
RFC 7234规范对缓存的控制有一定的局限性,因此有时候我们需要进行更加个性化的服务器端缓存控制。
.NET Core不仅提供了把Web服务器的内存用作缓存的内存缓存(in-memory cache),还提供了把Redis、数据库等用作缓存的分布式缓存(distributed cache)。
2. 客户端响应缓存
RFC7234是HTTP中对缓存进行控制的规范,其中重要的是cache-control响应报文头。
假如浏览器向服务器请求/Person/1这个路径,如果服务器端给浏览器端的响应报文头中cache-control的值为max-age=60,则表示服务器指示浏览器端”可以缓存这个响应内容60s”。
在60s内,如果用户要求浏览器再次向/Person/1发送请求的话,浏览器就可以直接使用保存的缓存内容,而不是向服务器再次发出请求。
在.NET Core中,我们一般不需要手动控制响应报文头中的cache-control,只要给需要进行缓存控制的控制器的操作方法添加ResponseCacheAttribute这个特性即可。
.NET Core会根据ResponseCacheAttribute的设置来生成合适的cache-control响应头。
下面验证一下:创建一个API项目,编写一个返回当前时间Now方法,如以下代码:
[HttpPost]
public DateTime NowTime()
{
return DateTime.Now;
}很显然,每次请求这个方法的时候,服务器都会返回当前时间,接下来,在Now方法前加上【ResponseCache(Duration=60)】,如以下代码:
[HttpPost]
[ResponseCache(Duration = 60)]
public DateTime NowTime()
{
return DateTime.Now;
}当我们第一次访问这个路径的时候,服务器端返回了当前的时间,从响应报文头中,我们看到了cache-control响应报文头,其中的max-age的值就是60。
浏览器看到这个报文头后,就会把响应内容缓存60s。
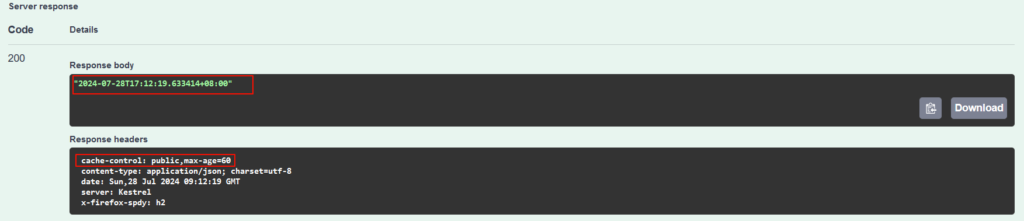
默认情况下,[ResponseCache]设置只通过生成cache-control响应报文头来控制客户端缓存。
如果客户端不支持客户端缓存,这个设置也是不生效的,毕竟是否使用缓存、如何使用缓存都由客户端决定的,cache-control响应报文头只是一个建议而已。
3. 服务器端响应缓存
如果我们在ASP.NET Core中安装了”响应缓存中间件(response caching middleware)”,ASP.NET Core不仅会继续根据[ResponseCache]设置来生成cache-control响应报文以设置客户端缓存,还会在服务器端也按照[ResponseCache]的设置来对响应进行服务器端缓存。
如果没有启用”响应缓存中间件”,那么当A、B、C这三个浏览器分别向Time方法发送请求的时候,服务器端的Time方法会执行三次;
如果启用了”响应缓存中间件”,当A、B、C这三个浏览器分别向Time方法发送请求的时候,只要后面两次请求在60s内,服务器端的Now方法只会执行一次,后两次请求虽然也会到达服务器,但是服务器会把第一次响应的缓存内容直接返回,而不会执行Time方法。
很显然,使用响应缓存中间件在服务器端实现响应缓存有两个好处:
- 提升没有实现缓存机制的客户端获取数据的速度,因为虽然请求仍然到达了服务器,但服务器端缓存直接返回了缓存的响应,避免了从执行速度缓慢的数据源获取数据的性能问题
- 对于实现了缓存机制的客户端也能降低服务器端的压力,因为如果没有启用响应缓存中间件,那么如果在短时间内服务器收到了来自一万个不同客户端到Time方法的请求,那么Time方法仍然会执行一万次,因为客户端的缓存是由每个客户端自己管理的
如果启用了响应缓存中间件,Time方法只会执行一次,这降低了服务器端的压力。
启用响应缓存中间件的步骤很简单,除了给控制器中需要进行缓存控制的操作方法标注[ResponseCache]之外,我们只要在ASP.NET Core项目的Program.cs的app.MapControllers之前加上app.UseResponseCaching即可。
注意:
如果项目启用了CORS,请确保app.UseCors写到app.UseResponseCaching之前
服务器端响应缓存有很多限制,包括但不限于:
响应状态码为200的GET或者HEAD响应才可能被缓存;
报文头中不能含有Authorization、Set-Cookie。
服务器端响应缓存的使用也比较复杂,如果设置不当的话,会导致缓存的数据错误,比如发送给用户A的响应被缓存起来,然后发送给用户B,导致数据安全风险。
由于服务器端响应缓存开发调试的麻烦以及过于苛刻的限制,因此除非开发人员能够灵活掌握并应用它,否则本文作者不建议启用”响应缓存中间件”。
对于只需要进行客户端响应缓存处理的操作方法,我们简单标注ResponseCacheAttribute即可;
如果还需要在服务器端进行缓存处理,建议开发人员采用APS.NET Core提供的内存缓存、分布式缓存等机制来编写程序,以更灵活地进行自定义缓存处理。
4. 内存缓存
除了响应缓存中间件这样自动化的服务器端缓存机制之外,ASP.NET Core还提供了允许开发人员手动进行缓存管理的机制,内存缓存就是一种把缓存数据放到应用程序内存中的机制。
内存缓存中保存的是一系列的键值对,就像Dictionary类型一样,每个不同的缓存内容具有不同的”缓存键”,每个缓存键对应一个”缓存值”。
我们可以设置缓存的键值对,也可以根据缓存键取出缓存中保存的缓存值。
内存缓存的数据保存在当前运行的网站程序的内存中,是和进程相关的。
因为在Web服务器中,多个不同网站是运行在不同的进程中的,所以不同网站的内存缓存是不会互相干扰的,而且网站重启后,内存缓存中的所有数据也就都被清空了。
对于.NET Core MVC项目,框架会自动地注入内存缓存服务;
对于.NET Core Web API等没有自动注入内存缓存服务的项目,我们需要在Program.cs的builder.Build之前添加builder.Services.AddMemoryCache来把内存缓存相关服务注册到依赖注入容器中。
在使用内存缓存的时候,我们主要使用IMemoryCache接口,这个接口有以下几个常用方法:

在进行开发的时候,经常用到的就是”尝试获取缓存值,如果获取不到缓存值,则从数据源获取数据,然后将其保存到缓存中”这样的操作,而且一般从数据源获取数据都是比较消耗资源的,因此获取数据的方法通常都是异步方法。
这里用GetOrCreateAsync来讲解IMemoryCache,然后编写GetBooks方法来从DbContext读取所有的图书,如以下代码所示:
[Route("api/[controller]/[action]")]
[ApiController]
public class CacheController(SQLServerDbContext _dbContext,IMemoryCache _cache,ILogger<CacheController> _log): ControllerBase
{
[HttpGet]
public async Task<Book[]> GetBooks()
{
_log.LogInformation("开始执行GetBooks方法");
Book[]? items = await _cache.GetOrCreateAsync("AllBooks", async async =>
{
_log.LogInformation("从数据库读取数据");
return await _dbContext.Books.Take(1000).ToArrayAsync();
});
_log.LogInformation("把数据返回给调用者");
return items!;
}
}在13~20行代码中,我们使用”AllBooks”作为缓存键到内存缓存中读取前1000条的图书;
如果缓存中没有对应的数据,则调用_dbContext.Books从数据库中获取数据,获取的数据除了会作为GetOrCreateAsync的返回值返回之外,我们也会把数据放到缓存中。
运行上面的程序,然后第一次访问/Cache/GetBooks,会在控制台中看到如图所示:
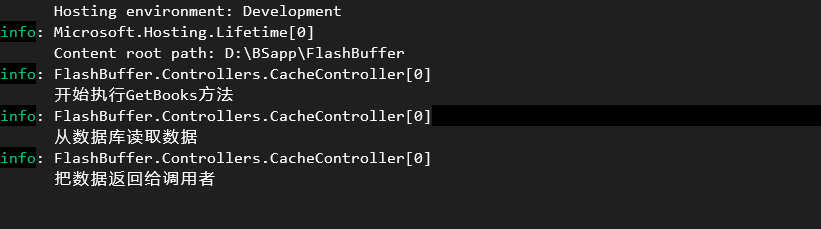
从日志的执行结果来看,由于这是我们第一次访问这个路径,缓存中还没有对应的数据,因此程序会先从数据库中查询出对应的数据,再把数据返回给调用者。
当我们第二次访问/Cache/GetBooks的时候,会在控制台看到不从数据库读取数据的输出内容:

由于这是我们第二次访问这个路径,缓存中已经存在对应的数据了,因此GetOrCreateAsync直接返回缓存的数据,而从数据库中获取数据的回调代码没有执行。
通过代码调试得知,缓存中的数据是不会过期的,除非应用程序重启或者通过调用Remove等方法进行删除。
这种情况下,如果数据库中的数据发生变化,而缓存中保存的还是旧数据,就会出现缓存数据和数据库中的数据不一致的情况。
我们可以通过设置缓存的过期时间来解决缓存数据不一致的问题,当过期时间到来的时候,对应的缓存数据会从缓存中被清除。
过期策略有”绝对过期时间”和”滑动过期时间”两种。
绝对过期时间指的是自设置缓存之后的指定时间后,缓存项被清除;
滑动过期时间指的是自设置缓存之后的指定时间后,如果对应的缓存数据没有被访问,则缓存项被清除,而如果在指定的时间内,对应的缓存数据被访问了一次,则缓存项的过期时间会自动续期。
我们先来看看绝对过期时间的用法。
GetOrCreateAsync方法的回调方法中有一个ICacheEntry类型的参数,通过ICacheEntry,我们可以对当前的缓存项进行更详细的设置,比如设置缓存项被清除的回调、设置缓存项的优先级等。
ICacheEntry的AbsoluteExpirationRelativeToNow属性是TimeSpan?类型的,用来设定缓存项的绝对过期时间,具体用法如以下代码:
[HttpGet]
public async Task<Book[]> GetBooks()
{
_log.LogInformation("开始执行Demo1:"+DateTime.Now);
Book[]? items = await _cache.GetOrCreateAsync("AllBooks", async(e) =>
{
//缓存绝对过期时间
e.AbsoluteExpirationRelativeToNow = TimeSpan.FromSeconds(10);
_log.LogInformation("从数据库读取数据");
return await _dbContext.Books.Take(100).ToArrayAsync();
});
_log.LogInformation("Demo1执行结束");
return items!;
}上面的第11行代码用来设置缓存键为”AllBooks”的缓存项的绝对过期时间为10s。
我们执行程序,然后连续访问3词Demo1方法的路径,其中第2次访问在第1次访问的10s内,而第3次访问在第一次访问的10s外。
程序执行结果如图:
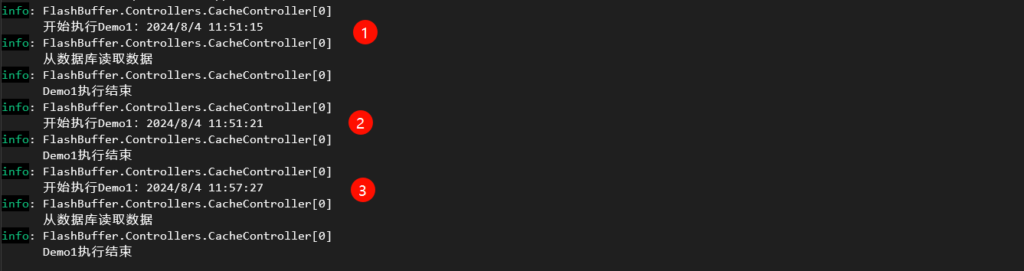
从程序运行结果可以看出:
第1次执行请求的时候,由于缓存中没有”AllBooks”对应的缓存数据,程序会从数据库中加载数据;
第2次执行请求的时候,由于距离第1次设置缓存数据只有不到1s,因此缓存中的数据有效,我们直接获取了缓存中的数据;
第3次执行请求的时候,由于距离第一次设置缓存数据已经过去几分钟了,因此缓存中的数据已经被删除,程序重新从数据库中加载数据。
我们再来看滑动过期时间的用法。
ICacheEntry的SlidingExpiration属性是TimeSpan?类型的,用来设定缓存项的滑动过期时间,具体用法如以下代码所示:
[HttpGet]
public async Task<Book[]> GetBooks()
{
_log.LogInformation("开始执行Demo2:"+DateTime.Now);
Book[]? items = await _cache.GetOrCreateAsync("AllBooks2", async(e) =>
{
//缓存绝对过期时间
//e.AbsoluteExpirationRelativeToNow = TimeSpan.FromSeconds(10);
//缓存滑动过期时间
e.SlidingExpiration = TimeSpan.FromSeconds(10);
_log.LogInformation("Demo2从数据库读取数据");
return await _dbContext.Books.Take(100).ToArrayAsync();
});
_log.LogInformation("Demo2执行结束");
return items!;
}运行程序,然后连续访问4次Demo2方法的路径,其中第2次访问是在第1次访问的10s内,而第3次访问在第1次访问的10s外,但是在第2次访问的10s内,第4次访问在第3次访问的10s外。
程序运行结果如图所示:
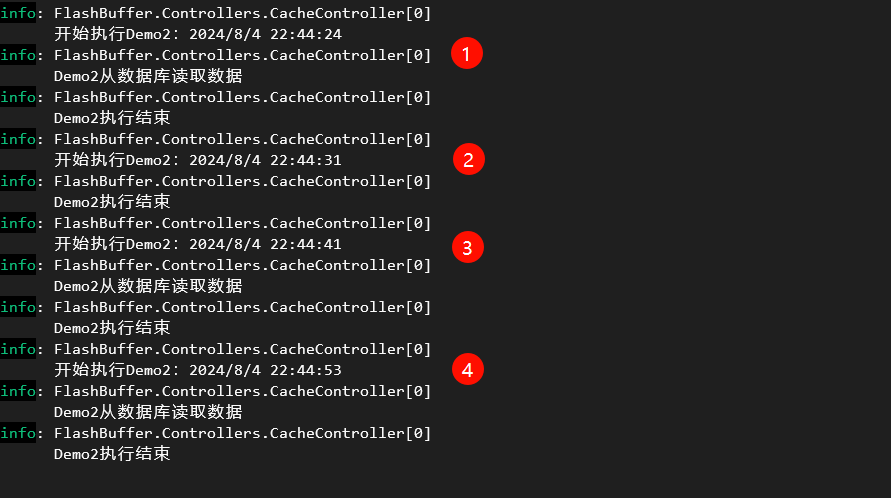
从程序运行结果可以看出:
第1次执行请求的时候,由于缓存中没有”AllBooks2″对应的缓存数据,因此程序会从数据库中加载数据;
第2次执行请求的时候,由于距离第1次设置缓存数据只有7s,因此缓存中的数据有效,我们直接获取了缓存中的数据,只要缓存数据被访问一次,设置了滑动过期时间的缓存内容会自动续期,因此”AllBooks2″对应的缓存内容有效期延长了10s;
第3次执行请求的时候,虽然距离第1次设置缓存数据已经过去17s了,但是由于第2次访问把缓存内容有效期延长了,因此缓存中的数据有效,我们获取了缓存中的数据,并且缓存项有效期又延长了10s;
第4次执行请求的时候,距离第3次访问已经过去了12s,因此缓存中的数据已经被删除,我们必须重新从数据库中加载数据。
设置绝对过期时间的缓存会在指定的时间后过期,这样即使发生缓存数据不一致的情况,只要我们设置的绝对过期时间比较短,这种不一致的情况也不会持续很长时间。
由于通过IMemoryCache设置的缓存数据是保存在内存中的,因此如果缓存的数据量非常大的话,这些数据会占据比较多的内存。
比如我们在系统中缓存用户的信息,我们设定的绝对过期时间为1min,如果系统中有1000万个用户被访问了,即使其中只有1万个用户经常被访问,而其他999万个用户只被访问了一次,这1000万个用户的数据也会保存在内存中1min。
这种情况下,我们可以采用滑动过期时间来保存用户的信息,并且设定滑动过期时间为10s,这样对于那999万个只被访问了一次的用户的数据,它们占据内存的时间只有10s,而另外1万个经常被访问的用户的数据由于频繁地被访问,因此它们的有效期可能会一直被延长,从而长期保存在缓存中。
使用滑动过期时间策略,我们可以保证经常访问的数据长期保存在缓存中,但是如果一个缓存项一直被频繁访问,那么这个缓存项就会一直被续期而不过期。
一旦发生缓存数据不一致的情况,我们设定了滑动过期时间策略的缓存项就得不到更新了。
这种情况下,我们可以对一个缓存项同时设置滑动过期时间和绝对过期时间,并且把绝对过期时间设定得比滑动过期时间长,这样缓存项会在绝对过期时间内随着访问被滑动续期,但是一旦超过了绝对过期时间,缓存项就会被删除,如以下代码所示:
_log.LogInformation("开始执行Demo3:"+DateTime.Now);
Book[]? items = await _cache.GetOrCreateAsync("AllBooks3", async(e) =>
{
//缓存绝对过期时间
e.AbsoluteExpirationRelativeToNow = TimeSpan.FromSeconds(30);
//缓存滑动过期时间
e.SlidingExpiration = TimeSpan.FromSeconds(10);
_log.LogInformation("Demo3从数据库读取数据");
return await _dbContext.Books.Take(100).ToArrayAsync();
});
_log.LogInformation("Demo3执行结束");可以看到,上面的第11行代码中我们设置了滑动过期时间为10s,第8行代码设置了绝对过期时间为30s。
然后我们多次请求这段代码,再看一下运行结果。
因为运行的次数比较多,程序日志输出的内容比较多,这里不再给出程序运行的截图,而是把程序运行结果汇总为一张表:
| 次数 | 时间 | 执行结果 |
| 1 | 14:07:10 | 没有命中缓存,执行数据库查询 |
| 2 | 14:07:18 | 命中缓存 |
| 3 | 14:07:30 | 没有命中缓存,执行数据库查询 |
| 4 | 14:07:38 | 命中缓存 |
| 5 | 14:07:46 | 命中缓存 |
| 6 | 14:07:54 | 命中缓存 |
| 7 | 14:08:02 | 没有命中缓存,执行数据库查询 |
从程序运行结果可以看出:
请求第1次执行的时候,由于缓存中没有”AllBooks3″对应的缓存数据,因此程序从数据库中加载数据;
请求第2次执行的时候,由于距离第1次执行只有8s,因此缓存被命中,并且缓存内容有效期延长了10s;
请求第3次执行的时候,由于距离第2次执行已经过去了12s,缓存内容已经被删除,因此缓存没有被命中,程序从数据库中加载数据;
在第4、5、6次执行的时候,由于距离上一次访问缓存仍然不足10s,因此缓存都被命中;
在第7次执行的时候,虽然距离上一次访问缓存仍然不足10s,不过距离上一次从数据库中加载数据已经超过了30s的绝对过期时间,因此对应的缓存内容已经被删除了,第7次没有缓存被命中。
由此可见,我们把绝对过期时间和滑动过期时间两种策略一起应用的话,既可以实现不经常被访问的数据不占用太长时间的缓存、经常被访问的缓存会高频率地被命中,又可以避免高频访问数据的缓存数据不一致的问题。
综上所述,我们在选择内存缓存的过期时间策略的时候,如果缓存项的条数不多或者大部分缓存数据被访问的频率都差不多的话,我们可以使用绝对过期时间策略;
如果只有部分数据访问频率比较高并且数据库中的数据不会被更新的话,我们可以使用滑动过期时间策略;
如果缓存项的数据量比较大且只有其中一部分会被频繁访问,而且数据库中的数据会被更新的话,用绝对过期时间和滑动过期时间混合的策略更合适。
5. 缓存穿透的问题的规避
在使用内存缓存的时候,如果处理不当,我们容易遇到”缓存穿透”的问题。
我们注意到,IMemoryCache接口中有一个Get(object key)方法,它用来根据缓存键key查找缓存值,如果找不到缓存项,则方法会返回null等默认值。
了解到这点,有的开发人员就用以下代码的方法来使用缓存:
public async Task<ActionResult<Book>>demo(Guid id)
{
//缓存键
string cacheKey = "Book" + id;
Book? b = _memoryCache.Get<Book>(cacheKey);
//如果缓存中没有数据
if (b == null)
{
b = await _bookDbContext.Books.FindAsync(id);
_memoryCache.Set(cacheKey, b);
}
if (b == null) return NotFound("找不到这本书"); else return b;
}上面的程序的逻辑很简单:
首先从缓存中查询是否有图书ID对应的缓存内容,如果Get方法返回null,则说明缓存中没有对应的数据,需要我们去数据库中查询,并且把查询的结果写入缓存。
在20行代码中,如果b仍然为null,说明缓存和数据库中都没有这条数据,程序就向客户端报告”这条数据找不到”。
这个程序能够正常执行,但是存在一个缺陷。
对于大部分正常请求,客户端发送的ID都是存在的图书ID,因此这些图书的信息都会保存到缓存中,之后无论有多少次针对这个ID的访问,程序都不再需要查询数据库,因此数据库的压力非常小。
但是针对在数据库中不存在的图书ID,在缓存中是不会保存任何信息的,因此第11行代码返回的值一直是null,我们就会在每次程序执行到第14行时进行数据库查询。
如果有恶意访问者使用不存在的图书ID来发送大量的请求,这样的请求就会一直执行第14行查询数据库的代码,因此数据库就会承受非常大的压力,甚至可能会导致数据库服务器崩溃,这种问题就叫作缓存穿透。
缓存穿透是由于”查询不到数据用null表示”导致的,因此解决的思路也很简单,就是我们把”查不到”也当成数据放入缓存。
在日常开发中只要使用GetOrCreateAsync方法即可,因为这个方法会把null也当成合法的缓存值,这样就可以轻松规避缓存穿透的问题了,如以下代码所示:
_log.LogInformation("开始执行Demo4" );
string cacheKey = "Book"+id;
Book? items = await _cache.GetOrCreateAsync(cacheKey, async (e) =>
{
Book? b = await _dbContext.Books.FindAsync(id);
_log.LogInformation("数据库查询:{0}",b==null?"为空":"不为空");
return b;
});
_log.LogInformation("Demo4执行结束:{0}",items==null?"为空":"不为空");
return items!;上面的程序运行后,我们访问这个Action两次,程序输出的日志如图所示:
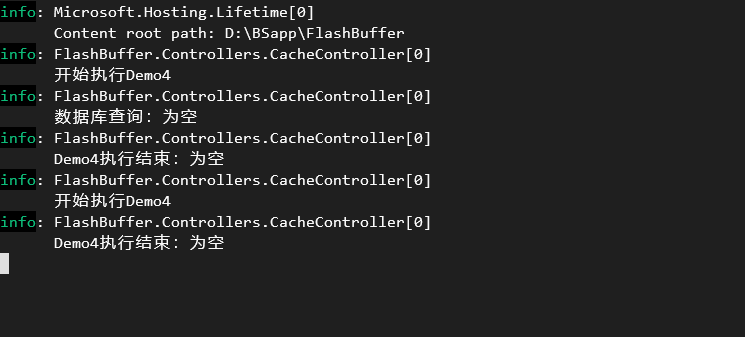
从程序运行结果可以看出,虽然程序第一次从数据库没有查询到对应的数据,但是第二次程序不会再执行数据库查询,这说明规避了缓存穿透的问题。
综上所述,在使用内存缓存的时候,应尽量使用GetOrCreateAsync方法。
6. 缓存雪崩问题的规避
在使用缓存的时候,有时会有在很短时间内,程序把一大批数据从数据源加入缓存的情况。
比如为了提升网站的运行速度,我们会对数据进行”预热”,也就是在网站启动的时候把一部分数据从数据库中读取出来并加入缓存。
如果这些数据设置的过期时间都相同,到了过期时间的时候,缓存项会集中过期。
因此又会导致大量的数据库请求,这样数据库服务器就会出现周期性的压力,这种陡增的压力甚至会把数据库服务器”压垮”(崩溃)。
当数据库服务器从崩溃中恢复后,这些压力又压了过来,从而造成数据库服务器反复崩溃、恢复,这就是数据库服务器的”雪崩”。
解决这个问题的思路也很简单,那就是写缓存时,在基础过期时间之上,再加上一个随机的过期时间,这样缓存项的过期时间就会均匀地分布在一个时间段内,就不会出现缓存集中一个时间点全部过期的情况了。
7. 缓存击穿问题的规避
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来
这些请求发现缓存过期一般都会从数据库服务器加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把数据库服务器压垮。
对于缓存击穿的规避我们可以不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间。
8. 缓存数据混乱的规避
在使用服务器端缓存的时候,如果处理不当,程序有可能造成缓存数据混乱等严重的问题。
如以下代码所示,这是用来获取当前书本详细信息的一段代码,其中存在数据泄漏问题。
[HttpGet]
public Book GetBookInfo(long id)
{
return _cache.GetOrCreate("BookInfo", (e) =>
{
return _dbContext.Books.Find(id);
})!;
}上面的代码使用”BookInfo”作为缓存键。
当A用户访问示例代码的API的时候,第8行代码查询到了A用户的书本信息,然后数据被写入到缓存中;
当B用户也来访问这个API的时候,由于缓存中已经存在缓存键为”BookInfo”的缓存内容,因此网站就直接把缓存中的数据返回给B用户了,但是缓存中的书本信息A用户的,这就是造成了B用户看到A用户信息的数据泄漏问题。
解决这种问题的核心就是要合理设置缓存的ID。
很显然,在上面代码中用缓存键”BookInfo”加上当前用户的ID作为缓存键就可以避免这个问题。
9. 分布式缓存
由于内存缓存把缓存保存在Web应用的内存中,因此数据的读写速度是非常快的。
但是在分布式系统中,这些缓存数据是不能共享的,因此集群中每个节点中的Web应用都要加载一份数据到自己的内存缓存中,如下图所示:
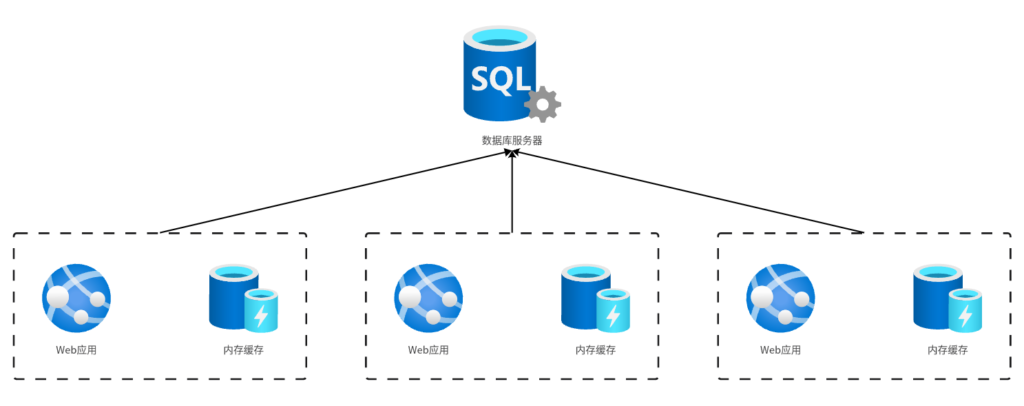
比如有一个到/Book/1的请求,这个请求被转发到A服务器,A服务器会从数据库中查询数据,然后将数据写入缓存;
如果又有一个到/Book/1的请求,并且这个请求也被转发到了A服务器,那么这个请求就可以使用内存中的缓存,但是如果这个请求被转发到了B服务器,那么B服务器仍然需要先从数据库中查询数据。
如果集群节点的数量不多的话,这样的重复查询不会对数据库服务器造成太大压力,各个Web应用维护自己的内存缓存即可;
但是如果集群节点的数量非常多的话,这样的重复查询也可能会把数据库服务器”压垮”。
同时,如果缓存的数据量很大的话,它们占用的内存空间也会比较大,这样每台服务器都需要配置比较大的内存,这也会增加服务器的硬件成本。
在分布式系统中,如果内存缓存不能满足要求的话,我们就需要把缓存数据保存到专门的缓存服务器中,所有的Web应用都通过缓存服务器进行缓存数据的写入和获取,这样的缓存服务器就叫作分布式缓存服务器,如图所示:
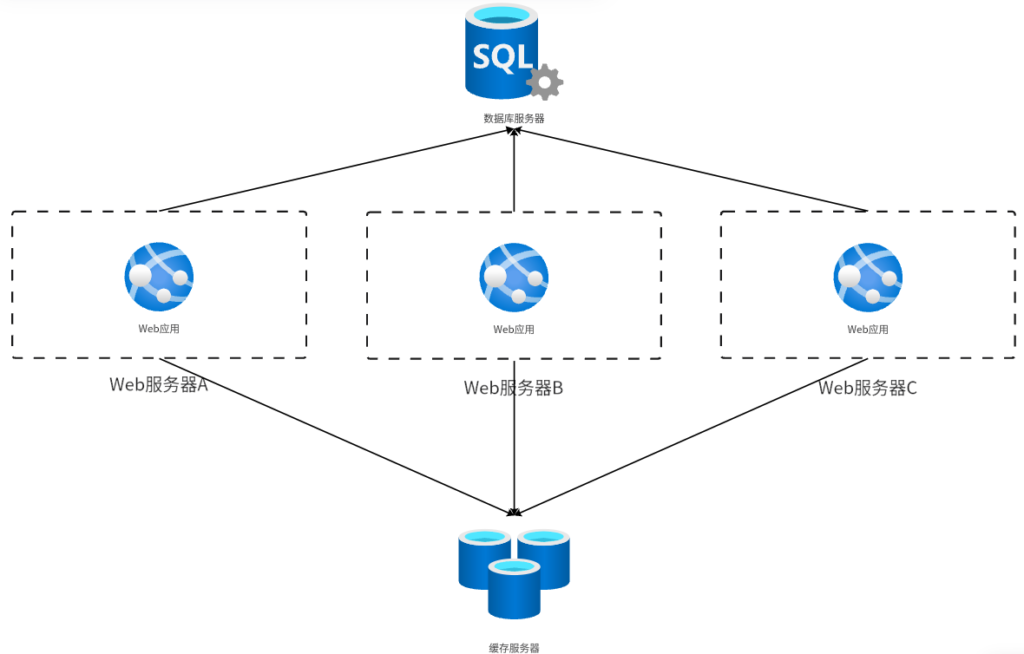
由于缓存数据被保存到一台公共的服务器中,一台服务器写入的缓存数据也可以被另外一台服务器读取到,因此我们就可以实现集群中的所有服务器共享一份缓存,从而避免各个服务器重复加载数据到本地内存缓存的问题。
常用的分布式缓存服务器有Redis、Memcached等,当然我们也可以把SQL Server等关系数据库当作分布式缓存服务器使用。
.NET Core中提供了统一的分布式缓存服务器的操作接口IDistributedCache,无论用什么类型的分布式缓存服务器,我们都可以统一使用IDistributedCache接口进行操作。
IDistributedCache同样支持绝对过期时间和滑动过期时间,分布式缓存中提供了DistributedCacheEntryOptions类用来配置过期时间,它的用法和内存缓存中的几乎一样,比如AbsoluteExpirationRelativeToNow属性用于设置绝对过期时间,SlidingExpiration属性用于设置滑动过期时间。
因为不同类型的分布式缓存服务器支持的缓存键和缓存值的数据类型不同。
为了简化操作,IDistributedCache统一规定缓存键的类型为string,缓存值的类型为byte[]类型。
缓存键的类型统一为string类型是合理的,而缓存值的类型统一为byte[]类型,这就要求我们在写入缓存的时候把其他数据类型转换为byte[]类型,而从缓存中查询数据的时候,需要我们再把读到的byte[]类型的数据转换为原始类型。
因为在日常开发中,string类型的缓存值比byte[]类型的更常用,所以.NET Core中还提供了一些按照string类型存取缓存值的扩展方法。
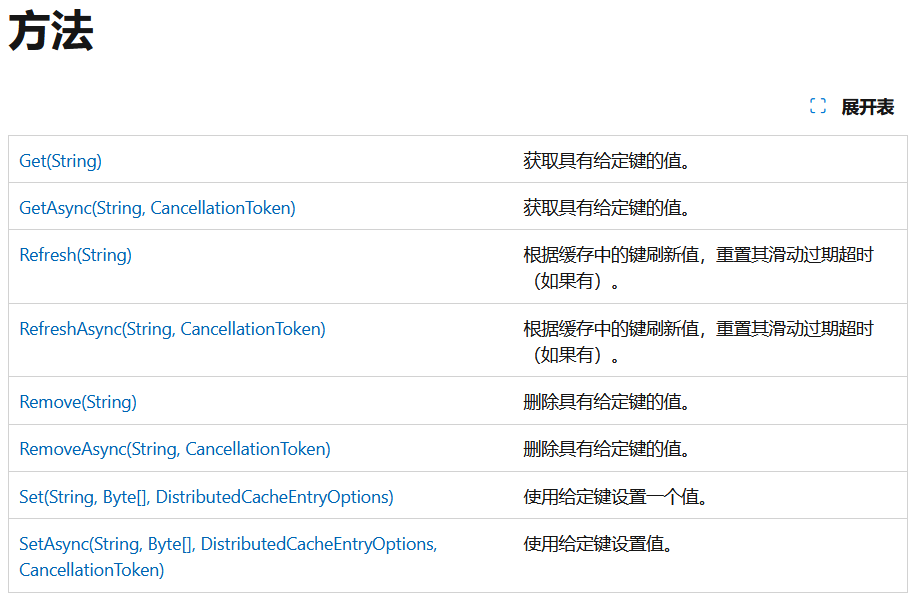
让我们来看一下IDistributedCache接口中定义的主要方法及主要的扩展方法:

在使用分布式缓存的时候,我们还要选择合适的缓存服务器。
微软官方提供了用SQL Server作为缓存服务器的DistributedSqlServerCache,但是用关系数据库来保存缓存的性能并不好。
Memcached是一个专门的缓存服务器,在缓存数据量比较小的时候,性能非常高,但是Memcached在集群、高可用等方面比较弱,而且有”缓存键的最大长度为250B”等限制。
如果要使用Memcached作为分布式缓存服务器,我们可以安装EnyimMemcachedCore这个第三方NuGet包。
Redis是一个键值对数据库,提供了丰富的数据类型,它不仅可以被当作缓存服务器,也可以用来保存列表、字典、集合、地理坐标等数据类型,更可以用来作为消息队列。
在某些情况下,Redis作为缓存服务器比Memcached性能稍差,但是Redis在高可用、集群等方面非常强大,非常适合在数据量大、需要高可用性等场合使用。
下面来演示一下如何使用分布式缓存服务器,以及如何在.NET中编写代码进行缓存操作。
首先,因为我们要连接的缓存服务器是Redis,所以需要通过NuGet安装Microsoft.Extensions.Caching.StackExchangeRedis。
其次,在Program.cs的builder.Builde之前添加以下代码:
builder.Services.AddStackExchangeRedisCache(options =>
{
options.Configuration = builder.Configuration["RedisConnection"];
options.InstanceName = "ichi";
});上面的第一行代码用来注册用Redis作为分布式缓存服务器的服务;
第四行代码用来设置程序到Redis服务器的连接配置。
Redis是一个键值对数据库,如果键命名不当,容易造成键名称冲突,从而导致数据混乱。
因为Redis服务器可能也在被其他程序使用,为了避免这里缓存的键值对和其他数据混淆,建议为缓存设置一个前缀。
上面的第五行代码就是用来设置缓存键的前缀的,IntanceName属性可以不设置,但是建议设置这个属性,并且为其设置一个和连接到Redis服务器的其他程序不冲突的值。
接下来,编写代码来通过IDistributedCache读写Redis中的缓存数据,如以下代码所示:
/// <summary>
/// StackExchangeRedis GetOrCreate
/// </summary>
/// <returns></returns>
[HttpGet]
public async Task<string> RedisSet()
{
string? cacheValue = await _distCache.GetStringAsync("Now");
if (cacheValue == null)
{
cacheValue = DateTime.Now.ToString();
DistributedCacheEntryOptions? opt = new()
{
AbsoluteExpirationRelativeToNow = TimeSpan.FromSeconds(30)
};
await _distCache.SetStringAsync("Now",cacheValue, opt);
}
return cacheValue;
}运行程序,然后访问这个Action。
查看Redis中的数据我们会发现Redis中的数据确实按照我们的设置缓存起来了,如下图所示:

10. 缓存方式的选择
经过前面的学习,我们知道.NET中的缓存分为客户端响应缓存、服务器端响应缓存、内存缓存、分布式缓存等。
缓存可以极大地提升系统的性能,在进行系统设计的时候,我们要根据系统的特点选择合适的缓存方式。
客户端响应缓存能够充分利用客户端的缓存机制,它不仅可以降低服务器端的压力,也能够提升客户端的操作响应速度并且降低客户端的网络流量。
但是我们需要合理设置缓存相关参数,以避免客户端无法及时刷新到最新数据的问题。
服务器端响应缓存能够让我们几乎不需要编写额外的代码就轻松地降低服务器的压力。
但是由于服务器端响应缓存的启用条件比较苛刻,因此要根据项目的情况决定是否使用它。
内存缓存能够降低数据库以及后端服务器的压力,而且内存缓存的存取速度非常快;
分布式缓存能够让集群中的多台服务器共享同一份缓存,从而降低数据源的压力。
如果集群节点的数量不多,并且数据库服务器的压力不大的话,推荐大家使用内存缓存,毕竟内存的读写速度比网络快很多;
如果集群节点太多造成数据库服务器的压力很大的话,可以采用分布式缓存。
无论是使用内存缓存还是分布式缓存,我们都要合理地设计缓存键,以免出现数据混乱。
这些缓存方式并不是互斥的,我们在项目中可以组合使用它们。
比如对于论坛系统,论坛首页中的版块信息变动不频繁,我们可以为版块信息的客户端响应缓存设置24h的过期时间;
对于所有的帖子详情信息,我们同时启用内存缓存和分布式缓存,当加载帖子详情页面的数据的时候,我们先到内存缓存中查找,内存缓存中找不到再到分布式缓存中查找,这样就既可以利用内存缓存读取数据快的优点,也能利用分布式缓存的优点。