
HashMap底层数据结构
我们现在用的都是 JDK 1.8,底层是由“数组+链表+红黑树”组成,而在 JDK 1.8 之前是由“数组+链表”组成
1.为什么JDK1.8要改成数组+链表+红黑树?
主要是为了提升在 hash 冲突严重时(链表过长)的查找性能,使用链表的查找性能是 O(n),而使用红黑树是 O(logn)
2.那什么时候用链表什么时候用红黑树
对于插入,默认情况下是使用链表节点。当同一个索引位置的节点在新增后达到9个(阈值8):如果此时数组长度大于等于 64,则会触发链表节点转红黑树节点(treeifyBin);而如果数组长度小于64,则不会触发链表转红黑树,而是会进行扩容,因为此时的数据量还比较小。
对于移除,当同一个索引位置的节点在移除后达到 6 个,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点(untreeify)。
3.为什么链表转红黑树的阈值是8?
我们平时在进行方案设计时,必须考虑的两个很重要的因素是:时间和空间。对于 HashMap 也是同样的道理,简单来说,阈值为8是在时间和空间上权衡的结果
红黑树节点大小约为链表节点的2倍,在节点太少时,红黑树的查找性能优势并不明显,付出2倍空间的代价作者觉得不值得。
理想情况下,使用随机的哈希码,节点分布在 hash 桶中的频率遵循泊松分布,按照泊松分布的公式计算,链表中节点个数为8时的概率为 0.00000006,这个概率足够低了,并且到8个节点时,红黑树的性能优势也会开始展现出来,因此8是一个较合理的数字。
4.那为什么转回链表节点是用的6而不是复用8?
如果我们设置节点多于8个转红黑树,少于8个就马上转链表,当节点个数在8徘徊时,就会频繁进行红黑树和链表的转换,造成性能的损耗。
5.那 HashMap 有哪些重要属性?分别用于做什么的?
除了用来存储我们的节点 table 数组外,HashMap 还有以下几个重要属性:1)size:HashMap 已经存储的节点个数;2)threshold:扩容阈值,当 HashMap 的个数达到该值,触发扩容。3)loadFactor:负载因子,扩容阈值 = 容量 * 负载因子。
6.threshold 除了用于存放扩容阈值还有其他作用吗?
在我们新建 HashMap 对象时, threshold 还会被用来存初始化时的容量。HashMap 直到我们第一次插入节点时,才会对 table 进行初始化,避免不必要的空间浪费
7.HashMap 的默认初始容量是多少?HashMap 的容量有什么限制吗?
默认初始容量是16。HashMap 的容量必须是2的N次方,HashMap 会根据我们传入的容量计算一个大于等于该容量的最小的2的N次方,例如传 9,容量为16
8.为什么 HashMap 的容量必须是 2 的 N 次方?
计算索引位置的公式为:(n – 1) & hash,当 n 为 2 的 N 次方时,n – 1 为低位全是 1 的值,此时任何值跟 n – 1 进行 & 运算会等于其本身,达到了和取模同样的效果,实现了均匀分布。实际上,这个设计就是基于公式:x mod 2^n = x & (2^n – 1),因为 & 运算比 mod 具有更高的效率
9.为什么HashMap 的默认初始容量是 16?
我认为是16的原因主要是:16是2的N次方,并且是一个较合理的大小。如果用8或32,我觉得也是OK的。实际上,我们在新建 HashMap 时,最好是根据自己使用情况设置初始容量,这才是最合理的方案。
10.负载因子默认初始值又是多少?
负载因子默认值是0.75
11.HashMap 的插入流程是怎么样的?
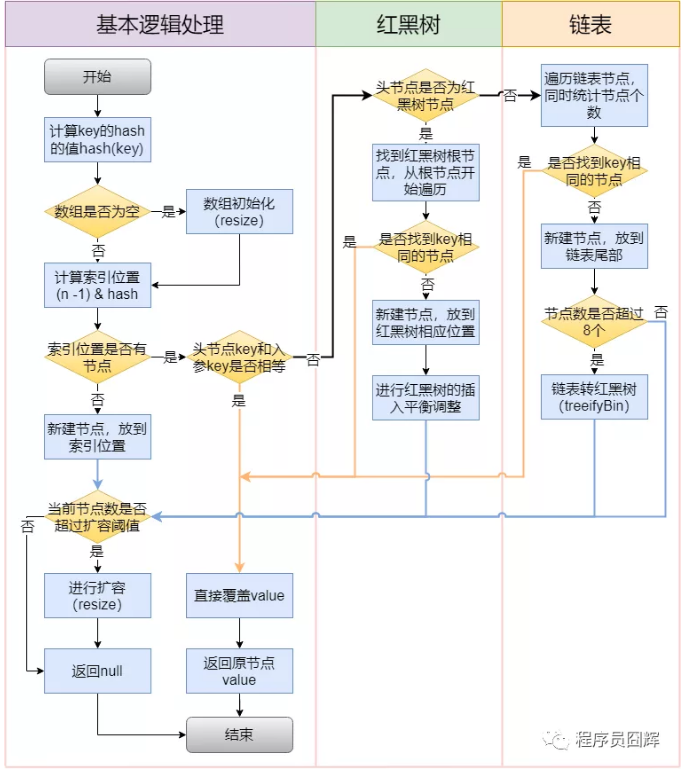
12.计算 key 的 hash 值,是怎么设计的?
拿到 key 的 hashCode,并将 hashCode 的高16位和 hashCode 进行异或(XOR)运算,得到最终的 hash 值。
13.为什么要将hashCode 的高16位参与运算?
主要是为了在 table 的长度较小的时候,让高位也参与运算,并且不会有太大的开销。
例如下图,如果不加入高位运算,由于 n – 1 是 0000 0111,所以结果只取决于 hash 值的低3位,无论高位怎么变化,结果都是一样的。
14.扩容(resize)流程介绍下?

15.为什么红黑树和链表都是通过 e.hash & oldCap == 0 来定位在新表的索引位置
扩容前 table 的容量为16,a 节点和 b 节点在扩容前处于同一索引位置。
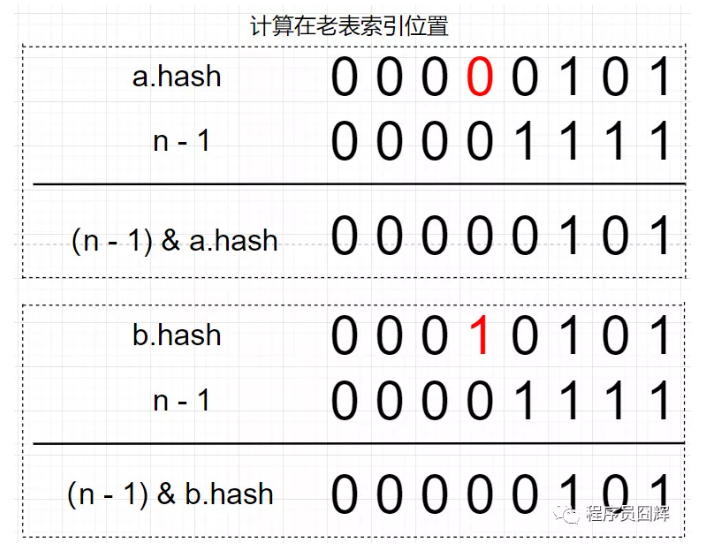
扩容后,table 长度为32,新表的 n – 1 只比老表的 n – 1 在高位多了一个1(图中标红)。
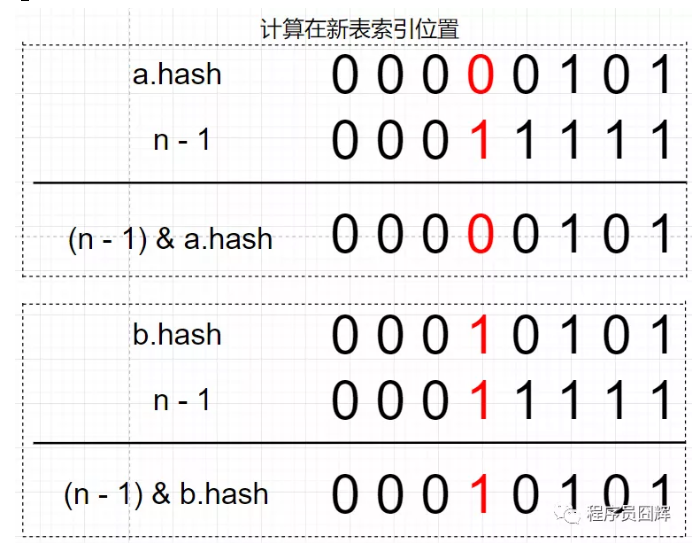
因为 2 个节点在老表是同一个索引位置,因此计算新表的索引位置时,只取决于新表在高位多出来的这一位(图中标红),而这一位的值刚好等于 oldCap。
因为只取决于这一位,所以只会存在两种情况:1) (e.hash & oldCap) == 0 ,则新表索引位置为“原索引位置” ;2)(e.hash & oldCap) == 1,则新表索引位置为“原索引 + oldCap 位置”。
16.HashMap 是线程安全的吗?
不是。HashMap 在并发下存在数据覆盖、遍历的同时进行修改会抛出 ConcurrentModificationException 异常等问题,JDK 1.8 之前还存在死循环问题。
17.介绍一下死循环问题?
导致死循环的根本原因是 JDK 1.7 扩容采用的是“头插法”,会导致同一索引位置的节点在扩容后顺序反掉。而 JDK 1.8 之后采用的是“尾插法”,扩容后节点顺序不会反掉,不存在死循环问题。
18.HashMap在JDK 1.8 主要进行了哪些优化?
JDK 1.8 的主要优化刚才我们都聊过了,主要有以下几点:
1)底层数据结构从“数组+链表”改成“数组+链表+红黑树”,主要是优化了 hash 冲突较严重时,链表过长的查找性能:O(n) -> O(logn)。
2)计算 table 初始容量的方式发生了改变,老的方式是从1开始不断向左进行移位运算,直到找到大于等于入参容量的值;新的方式则是通过“5个移位+或等于运算”来计算。
3)优化了 hash 值的计算方式,让高16位参与了运算。
4)扩容时插入方式从“头插法”改成“尾插法”,避免了并发下的死循环。
5)扩容时计算节点在新表的索引位置方式从“h & (length-1)”改成“hash & oldCap”,性能可能提升不大,但设计更巧妙、更优雅。
19.除了 HashMap,还用过哪些 Map,在使用时怎么选择?
