
一.NoSQL(非关系型数据库)
NoSQL 不仅仅是SQL
NoSQL不依赖业务逻辑方式存储,而以简单的key-value模式存储,从而大大增加了数据的库的扩展能力
NoSQL适用场景
对数据的高并发的读写
海量数据的读写
对数据高可扩展性
NoSQL不适用场景
需要事务支持
需要条件查询
NoSQL的几种类型:
Memcached、Redis
MangoDB、Hbase
根据业务需求 使用不同的数据库
二.Redis介绍
Redis(Remote Dictionary Server )
即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value非关系型数据库,并提供多种语言的API
Redis 与其他 key – value 缓存产品有不同的以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。 Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。 Redis支持数据的备份,即master-slave模式的数据备份。
三.Redis五大数据类型和数据结构
Redis是key + value的存储系统
Redis-key类型
①key的命名规则不同于一般语言,键盘上除了空格、换行外其他的大部分字符都可以使用
②我们在使用的时候可以自己定义一个key的格式
③key不要太长。占内存,查询慢
key的输出语句:
Keys * : 查询数据库所有的键
Exists :判断某个键是否存在
Type : 查看键的类型
del : 删除某个键
ttl : 值还有多少秒过期
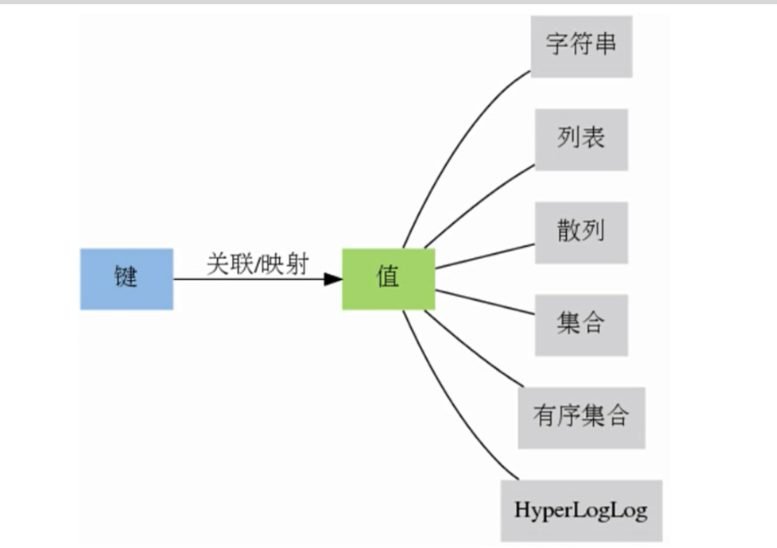

Value值类型:String、Set、List、Hash、Zset
String 类型:
是Redis最基本的类型,一个Key对应一个Value 也是用的最多的数据类型
List类型:
单键多个值
Set类型:
Redis的Set是String类型的无序集合。
它底层其实是一个Value为空的Hash表
所以它的增删改的复杂度都是O(1)
Hash类型:
Redis hash 是一个键值对集合
Redis hash 是一个String类型的field和Value的映射表
特别适合存储对象
Zset类型:
Redis中最复杂的数据类型
Redis有序集合Zset和无序集合Set非常相似,是一个没有重复元素的字符串集合
不同之处是有序集合的每个成员都关联了一个评分(Score)
这个评分被用来按照从低到高分的方式排序集合中的成员,集合的成员是唯一的
但是评分可以是重复的
四.Redis事务
与关系型数据库中的事务不同 没有事务四大特性
Redis事务是一个单独的隔离操作:
事务中的所有命令都会被序列化、按顺序地执行。
事务在执行的过程中,不会被其他客户端发送来的命令请求所打断
Redis事务的主要作用就是串联多个命令防止别的命令插队
更像一个批量执行指令的功能
一个事务从开始到执行会经历以下三个阶段: 开始事务 命令入队 执行事务
Redis事务的三个特性
①单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
②没有隔离级别的概念:队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在”事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题
③不保证原子性:redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
事务的错误处理
①组队中某个命令出现了报告错误,执行时整个的所有队列都会被取消
②如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚
事务的五个常用命令
①DISCARD92
取消事务,放弃执行事务块内的所有命令
②EXEC
执行所有事务块内的命令
③MULTI
标记一个事务块的开始
④UNWATCH
取消WATCH命令对所有Key的监视
⑤WATCH KEY
监视一个或者多个Key
五.Redis的持久化
Redis提供了2个不同形式的持久化方式
RDB :Redis DataBase
AOF: Append Of Firl
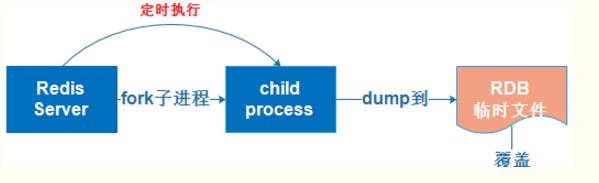
RDB(快)
在指定的时间间隔内将内存中的数据集快照写入磁盘
它恢复时是将快照文件直接读到内存里
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘
实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储
AOF(慢)
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。
六.Redis主从复制(降低读写压力 )
主从复制,就是主机数据更新后根据配置和策略
自动同步到备机的master/slave以读为主
用处:读写分离,性能扩展,容灾快速恢复
不能减少内存压力 只能减少读写压力
主从复制的原理(重中之重):
1.binlog输出线程:每当有从库连接到主库的时候,主库都会创建一个线程然后发送binlog内容到从库。在从库里,当复制开始的时候,从库就会创建两个线程进行处理:
2.从库I/O线程:当START SLAVE语句在从库开始执行之后,从库创建一个I/O线程,该线程连接到主库并请求主库发送binlog里面的更新记录到从库上。从库I/O线程读取主库的binlog输出线程发送的更新并拷贝这些更新到本地文件,其中包括relay log文件。
3.从库的SQL线程:从库创建一个SQL线程,这个线程读取从库I/O线程写到relay log的更新事件并执行。可以知道,对于每一个主从复制的连接,都有三个线程。拥有多个从库的主库为每一个连接到主库的从库创建一个binlog输出线程,每一个从库都有它自己的I/O线程和SQL线程。
当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
如果这是 slave node 初次连接到 master node,那么会触发一次
full resynchronization 全量复制。此时 master 会启动一个后台线程,开始生成一份
RDB 快照文件,同时还会将从客户端 client 新收到的所有写命令缓存在内存中。
RDB 文件生成完毕后, master 会将这个
RDB 发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中,接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
7.哨兵模式
一主二从三哨兵
哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能:
- 集群监控:负责监控 redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。 哨兵的核心知识
- 哨兵至少需要 3 个实例,来保证自己的健壮性。
- 哨兵 + redis 主从的部署架构,是不保证数据零丢失
的,只能保证 redis 集群的高可用性。
- 对于哨兵 + redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
8.Redis集群
Redis集群实现了对Redis水平扩容
即启动N个redis节点
将整个数据库储存分布存储在这N个节点中
9.Redis缓存中的雪崩,穿透,击穿
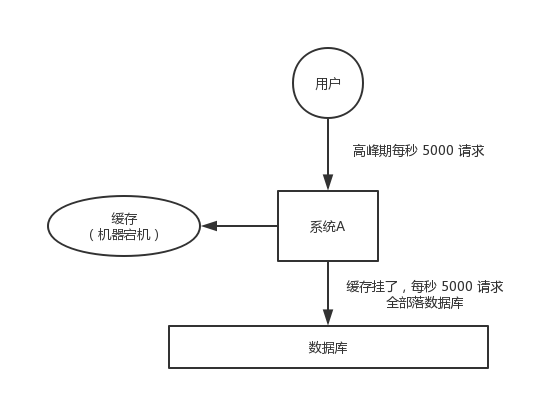
缓存雪崩
对于系统 A,假设每天高峰期每秒 5000 个请求,本来缓存在高峰期可以扛住每秒 4000 个请求,但是缓存机器意外发生了全盘宕机。缓存挂了,此时 1 秒 5000 个请求全部落数据库,数据库必然扛不住,它会报一下警,然后就挂了。此时,如果没有采用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。
这就是缓存雪崩。
缓存雪崩的事前事中事后的解决方案如下。
- 事前:redis 高可用,主从+哨兵,redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + hystrix 限流&降级,避免 MySQL 被打死。
- 事后:redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
缓存穿透
对于系统A,假设一秒 5000 个请求,结果其中 4000 个请求是黑客发出的恶意攻击。
黑客发出的那 4000 个攻击,缓存中查不到,每次你去数据库里查,也查不到。
举个栗子。数据库 id 是从 1 开始的,结果黑客发过来的请求 id 全部都是负数。这样的话,缓存中不会有,请求每次都“视缓存于无物”,直接查询数据库。这种恶意攻击场景的缓存穿透就会直接把数据库给打死。
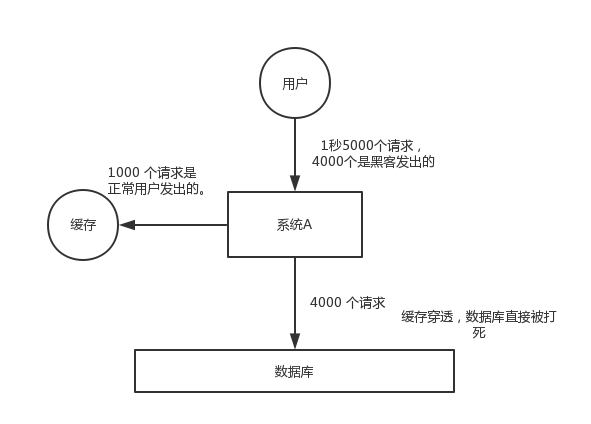
解决方法:每次系统 A 从数据库中只要没查到,就写一个空值到缓存里去。然后设置一个过期时间,这样的话,下次有相同的 key 来访问的时候,在缓存失效之前,都可以直接从缓存中取数据。
缓存击穿
缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况,当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
解决方式也很简单,可以将热点数据设置为永远不过期;或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。